Jinyu Li a personal journal
Gauge Ambiguity
18 Jan 2017 - 5 minute read在求解优化问题时,存在一种现象叫做 Gauge Ambiguity 。我们来看一个简单的例子:
假设在一条直线上有 $n$ 个质点,在直线上建立一维坐标系,用 $x_1, x_2, \dots, x_n$ 表示它们在这一坐标系下的坐标。现在用一把尺子测量任意两点间的距离,记 $x_i$ 点和 $x_j$ 点间的距离为 $d_{ij}$ ,每次测量带有相同的误差,且误差是零偏的。试求解每个点的坐标。
如果我们不假思索地开始写最小二乘,可以得到下面的目标优化:
\[\min \sum_{i\neq j}\left(\sqrt{(x_i-x_j)^2} - d_{ij}\right)^2.\]但是且慢!稍微留心就可以发现:如果我们将所有的点沿着直线滑动相同的路程,这个目标优化的值不会受到任何的影响!
这种现象便叫做 Gauge Ambiguity ,是当优化变量关于外部坐标系定义,但优化能量本身与外部坐标系的选取无关时发生的现象。在这种情况下,对于任意一个最优解,我们总可以更换一下坐标系,于是就可以得到一个新的最优解。换句话说就是最优解并不唯一(有无限多)。
解决 GA 的最简单方法是采用一个与优化变量绑定的坐标系。例如上面的问题中,我们可以把 $x_1$ 定义为原点,这时就有 $x_1 = 0$ ,也就是我们固定了 $x_1$ 的值。此时剩余的变量上就不存在这个问题了(但是解还是有两个,互相镜像,这可以通过适当选取初始值来区分)。
那么在优化中,GA 会产生什么问题呢?以上面的问题为例,如果我们计算一下 $n=2,3,4$ 个质点的情形下对应的 Jacobian 就会发现发现:任何一个 Jacobian ,它的最后一列都等于左侧三列相加,这意味着每个 Jacobian 都是秩亏的。这便是 GA 带来的问题。一般来说,当我们总的变量数是 $n$ ,而外部坐标系的维度是 $k$ 时,问题的 Jacobian 的秩不大于 $n-k$ 。
前面我们介绍过,在 Jacobian 秩亏时,采用 LM 算法的最小二乘优化仍能鲁棒地收敛。然而此时算法采用的是最速下降步,这意味着算法的收敛速度会大打折扣。因此,如果在问题中存在 GA,应该首先尝试修改问题回避它,才能使优化更加高效。
Kalman Filter(二)
17 Jan 2017 - 9 minute read继续上文,我们来边缘化 $x_{k-1}$ 。我们将上文中优化的标准方程写出来:
\[\begin{pmatrix} R_k^{-1} & -R_k^{-1}H_k & 0 \\ -H_k^TR_k^{-1} & H_k^TR_k^{-1}H_k+Q_k^{-1} & -Q_k^{-1}F_k \\ 0 & -F_k^TQ_k^{-1} & F_k^TQ_k^{-1}F_k+P_{k-1}^{-1} \end{pmatrix}\begin{pmatrix}z_k \\ x_k \\ x_{k-1} \end{pmatrix} = \begin{pmatrix} 0 \\ Q_k^{-1}B_ku_k \\ P_{k-1}^{-1}\hat{x}_{k-1 \given k-1} - F_k^T Q_k^{-1}B_ku_k \end{pmatrix}\]边缘化 $x_{k-1}$ 对应于用 $Q_k^{-1}F_k(F_k^TQ_k^{-1}F_k+P_{k-1}^{-1})^{-1}$ 乘上第三行后加到第二行上。这么做之后,经过一系列(耐心的)整理后,可以得到下面的边缘化标准方程:
\[\begin{pmatrix} R_k^{-1} & -R_k^{-1}H_k \\ -H_k^TR_k^{-1} & H_k^TR_k^{-1}H_k+P_{k|k-1}^{-1} \end{pmatrix}\begin{pmatrix}z_k \\ x_k \end{pmatrix} = \begin{pmatrix} 0 \\ P_{k|k-1}^{-1}\hat{x}_{k|k-1} \\ \end{pmatrix}\]这里 \(\hat{x}_{k \given k-1} = B_ku_k+F_k\hat{x}_{k-1\given k-1}\) 是已知 $x_{k-1}$ 的概率分布时 $x_k$ 的后验概率分布的期望;而 \(P_{k \given k-1} = F_kP_{k-1}F_k^T+Q_k\) 是它的协方差。
如果将上面的式子左侧进行块状 LDL 分解并依此进行整理,我们可以发现这个边缘化标准方程对应了一个新的(边缘化)最小二乘问题:
\[\min \left\|\begin{pmatrix}I & -H_k \\ 0 & I\end{pmatrix}\begin{pmatrix}z_k \\ x_k\end{pmatrix}-\begin{pmatrix}0 \\ \hat{x}_{k|k-1}\end{pmatrix}\right\|_{\Sigma_{k|k-1}^{-1}}^2\]这里的 \(\Sigma_{k \given k-1}\) 是什么不妨自己根据前面的推导来观察一下。
此时,只要再条件化 $z_k$ ,我们就可以求解此时最优的 $x_k$ 了。不过在此之前我们先整理一下思路:
- 我们知道了 $x_{k-1}$ 的分布;
- 我们把 $x_{k-1}$ 的分布利用边缘化“浓缩”进了 $x_k$ 。
如果此后 $x_{k-1}$ 不再发生任何的改变,那么我们这种“浓缩”便是准确的。但是我们会看到,在很多问题里,我们会得到关于 $x_{k-1}$ 的新信息,这时这么做就会丢失掉这些有用的信息。这也是 Kalman Filter 的缺点,但是要想完全避免这个问题是很难的,也是研究的一个重点。
小软件:ReNamer
16 Jan 2017 - 2 minute read
ReNamer
ReNamer is a very powerful and flexible file renaming tool, which offers all the standard renaming procedures, including prefixes, suffixes, replacements, case changes, as well as removing contents of brackets, adding number sequences, changing file extensions, etc. For advanced users there is support for Regular Expressions and a PascalScript rule, which lets users program their very own renaming rule.
界面简洁,功能强大的文件批量重命名工具。这个简直是日常工作救星!
Kalman Filter(一)
15 Jan 2017 - 9 minute readKalman Filter 是一种用途非常广泛的参数估计方法。毫不过分地说,它是当今参数估计中的 The Golden Standard Method 。相关的文献、参考资料也很多了,这里我们不再详细介绍这些基本知识。
参考 Wikipedia 上关于 Kalman Filter 的相关数学符号,设一个离散线性系统的状态迁移方程和观测方程为
\[\begin{aligned} x_k &= F_k x_{k-1} + B_k u_k + w_k \\ z_k &= H_k x_k + v_k. \end{aligned}\]已知 $x_{k-1} \sim N(\hat{x}_{k-1|k-1}, P_{k-1})$ 、$w_k \sim N(0, Q_k)$ 、$v_k \sim N(0, R_k)$ 、$u_k$ 时 ,系统中未知的 $x_k$ 和 $x_{k-1}$ 的真值的最大后验概率估计对应于下面的最小二乘的解:
\[\min \|x_{k-1}-\hat{x}_{k-1|k-1}\|_{P_{k-1}^{-1}}^2+\|x_k - F_k x_{k-1} - B_k u_k\|_{Q_k^{-1}}^2+\|z_k-H_kx_k\|_{R^{-1}}^2\]调整变量和余项的顺序,将它们合并成矩阵表示,我们可以得到
\[\min \left\|\begin{pmatrix} I & -H_k & 0 \\ 0 & I & -F_k \\ 0 & 0 & I \end{pmatrix}\begin{pmatrix} z_k \\ x_k \\ x_{k-1} \end{pmatrix} - \begin{pmatrix} 0 \\ B_k u_k \\ \hat{x}_{k-1|k-1} \end{pmatrix}\right\|_{\Sigma^{-1}}^2.\]其中,$\Sigma = \mathrm{diag}(R_k, Q_k, P_{k-1})$.
上面的余项中有三行,我们从下向上来看的话就是:
- 第三行对应 $x_{k-1}$ 的先验概率
- 第二行对应 $x_{k-1}$ 和 $x_k$ 的联合概率
- 第一行对应 $x_k$ 和 $z_k$ 的联合概率
为什么要倒着看呢?因为它蕴含了 Kalman Filter 系统模型里的结构。注意到我们这里的问题中系数矩阵是一个下三角矩阵。把这个问题当做一个线性系统,那么在高斯消元的顺序下,我们应该是先求解 $x_{k-1}$ ,然后代入求解 $x_k$ ,最后再代入求解 $z_k$ (实际上我们并不会这么做,因为 $z_k$ 是已知量,我们要对它条件化)。
回忆前面介绍过的线性最小二乘求解时边缘化、条件化问题。$x_{k-1}$ 被边缘化了,可以独立于其它变量求解,这意味着在其它变量未知时,$x_{k-1}$ 的概率与其它变量无关。而 $x_k$ 的概率分布取决于 $x_{k-1}$ 。也就是说这其中存在一个因果关系(Causality),其中 $x_{k-1}$ 是因,$x_k$ 是果。
同样地,$x_k$ 到 $z_k$ 也存在着因果关系。这些因果关系对应了下面有向图中实线的部分,而它也对应了前面系数矩阵中所有对角线外的非零元:
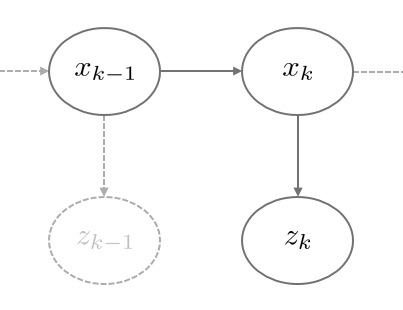
在 $z_k$ 已知时(也就是观测到了 $z_k$),我们便可以将其条件化,系统中剩余了 $x_{k-1}$ 和 $x_k$ 。如果同时将 $x_{k-1}$ 边缘化掉,剩下 $x_k$ ,我们就得到了 Kalman 滤波对 $x_k$ 的估计。
